
Asymmetric Cross-Guided Attention Network for Actor and Action Video Segmentation From Natural Language Query, ICCV 2019
Published in ICCV, 2019
Abstract
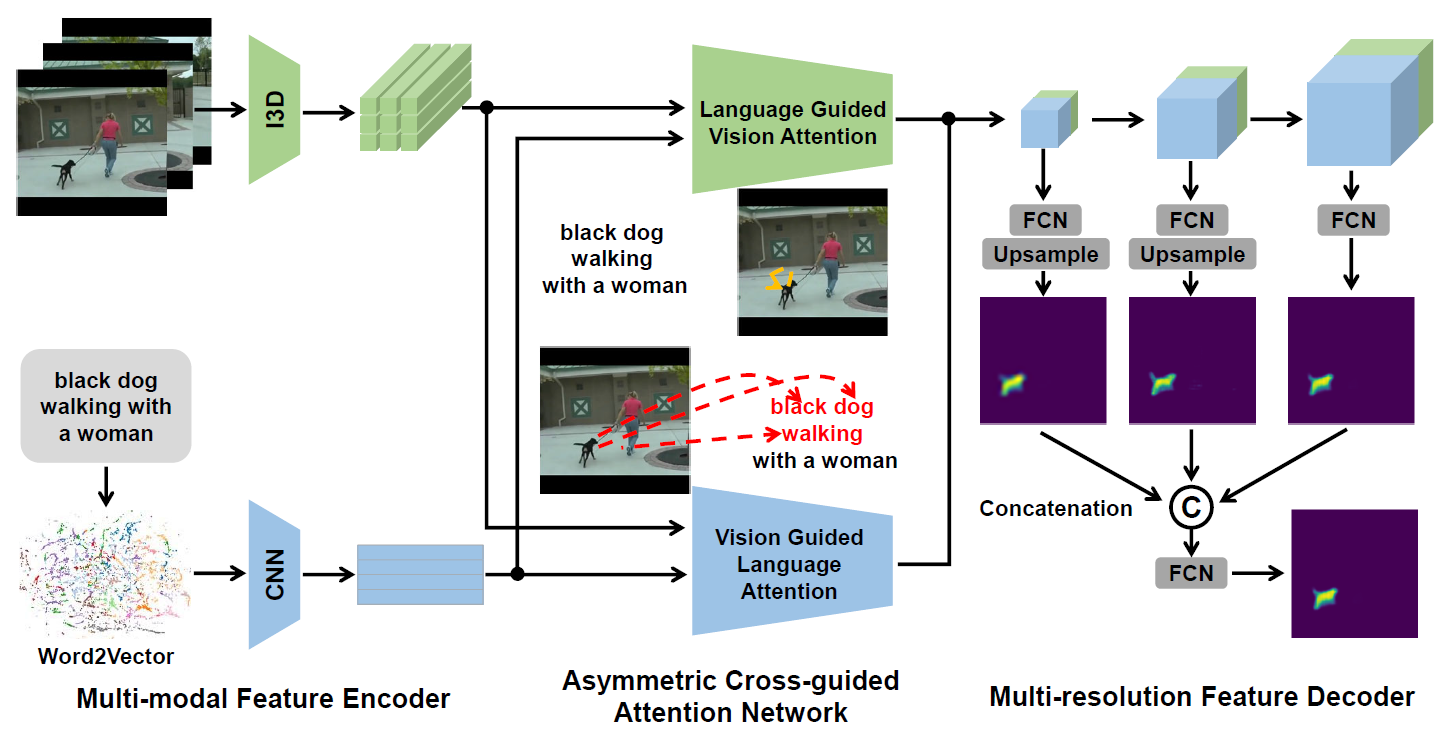
Actor and action video segmentation from natural language query aims to selectively segment the actor and its action in a video based on an input textual description. Previous works mostly focus on learning simple correlation between two heterogeneous features of vision and language via dynamic convolution or fully convolutional classification. However, they ignore the linguistic variation of natural language query and have difficulty in modeling global visual context, which leads to unsatisfactory segmentation performance. To address these issues, we propose an asymmetric cross-guided attention network for actor and action video segmentation from natural language query. Specifically, we frame an asymmetric cross-guided attention network, which consists of vision guided language attention to reduce the linguistic variation of input query and language guided vision attention to incorporate query-focused global visual context simultaneously. Moreover, we adopt multiresolution fusion scheme and weighted loss for foreground and background pixels to obtain further performance improvement. Extensive experiments on Actor-Action Dataset Sentences and J-HMDB Sentences show that our proposed approach notably outperforms state-of-the-art methods.
Framework
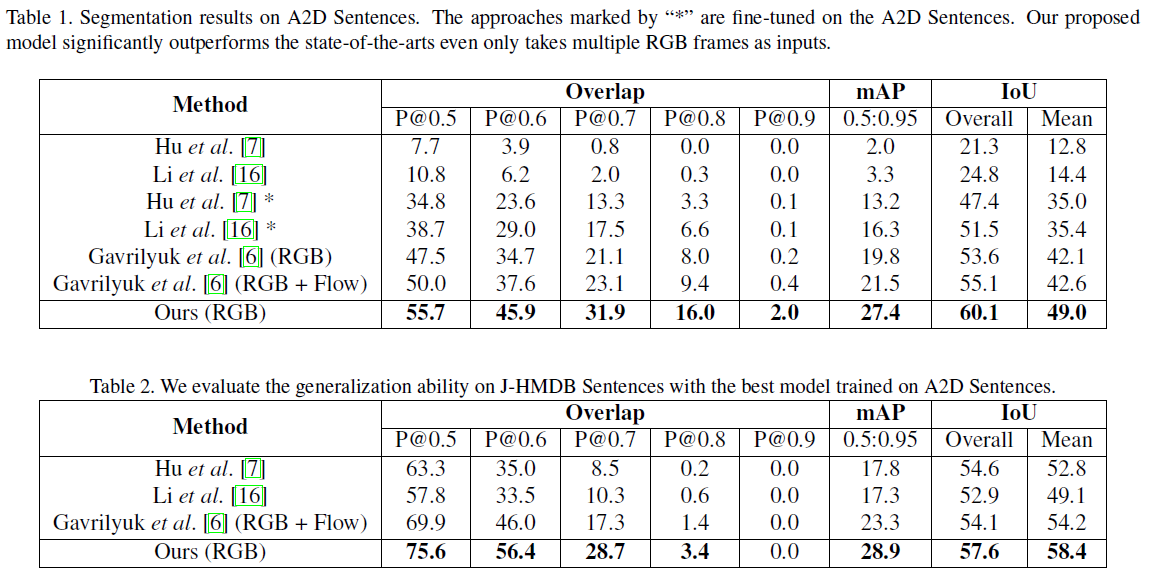
Result

Download
Citation
If you found this code useful, please cite the following paper:
@inproceedings{wang2019asymmetric,
title={Asymmetric Cross-Guided Attention Network for Actor and Action Video Segmentation From Natural Language Query},
author={Wang, Hao and Deng, Cheng and Yan, Junchi and Tao, Dacheng},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={3939--3948},
year={2019}
}
Concat
Hao Wang: hwang_xidian@163.com