
Exploring Hybrid Spatio-Temporal Convolutional Networks for Human Action Recognition, MTAP 2017
Published in Journal Multimedia Tools and Applications, 2017
Abstract
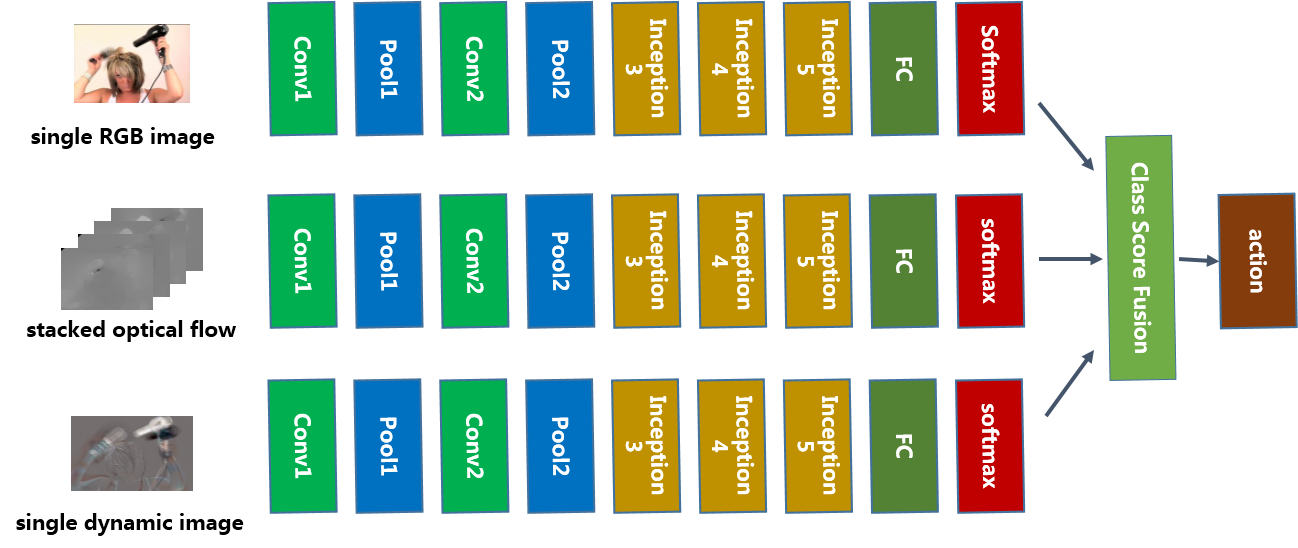
Convolutional neural networks have achieved great success in many computer vision tasks. However, it is still challenging for action recognition in videos due to the intrinsically complicated space-time correlation and computational difficult of videos. Existing methods usually neglect the fusion of long term spatio-temporal information. In this paper, we propose a novel hybrid spatio-temporal convolutional network for action recognition. Specifically, we integrate three different type of streams into the network: (1) the image stream utilizes still images to learn the appearance information; (2) the optical stream captures the motion information from optical flow frames; (3) the dynamic image stream explores the appearance information and motion information simultaneously from generated dynamic images. Finally, a weighted fusion strategy at the softmax layer is utilized to make the class decision. With the help of these three streams, we can take full advantage of the spatio-temporal information of the videos. Extensive experiments on two popular human action recognition datasets demonstrate the superiority of our proposed method when compared with several state-of-the-art approaches
Framework
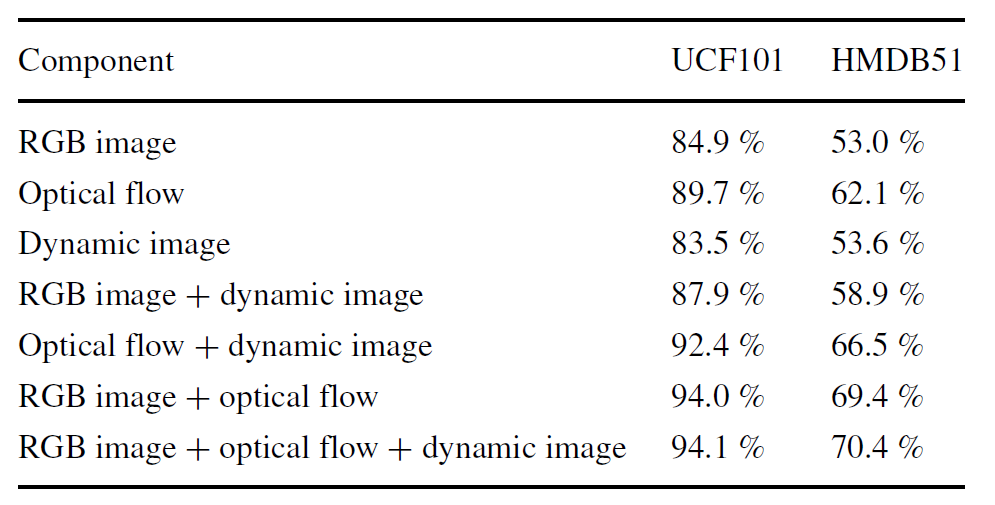
Result
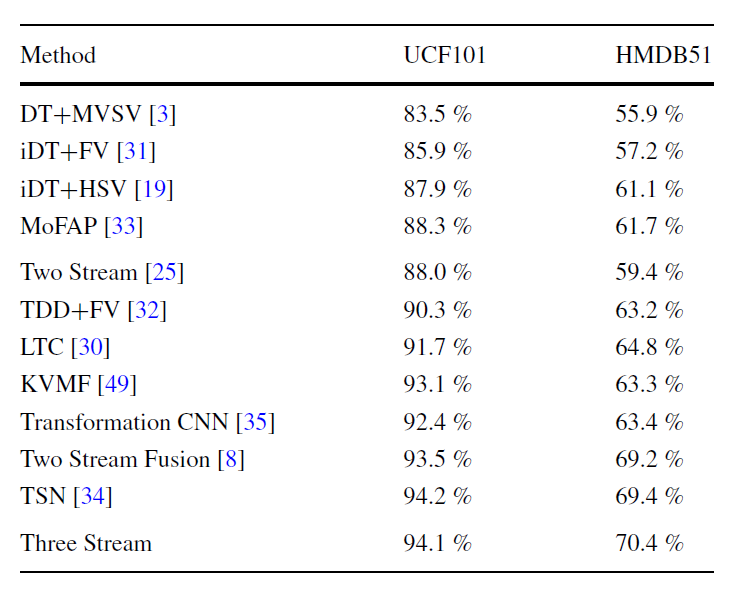
Download
Citation
Please cite the following if you find the code useful.
@Article{Wang2017, author=”Wang, Hao and Yang, Yanhua and Yang, Erkun and Deng, Cheng”,
title=”Exploring hybrid spatio-temporal convolutional networks for human action recognition”,
journal=”Multimedia Tools and Applications”,
year=”2017”, month=”Jul”, day=”01”,
volume=”76”, number=”13”, pages=”15065–15081”, issn=”1573-7721”,
doi=”10.1007/s11042-017-4514-3”,
url=”https://doi.org/10.1007/s11042-017-4514-3” }
Concat
Hao Wang: hwang_xidian@163.com